Context Engineering for Agents: A Goal, a Map, and a Way to Know It Arrived

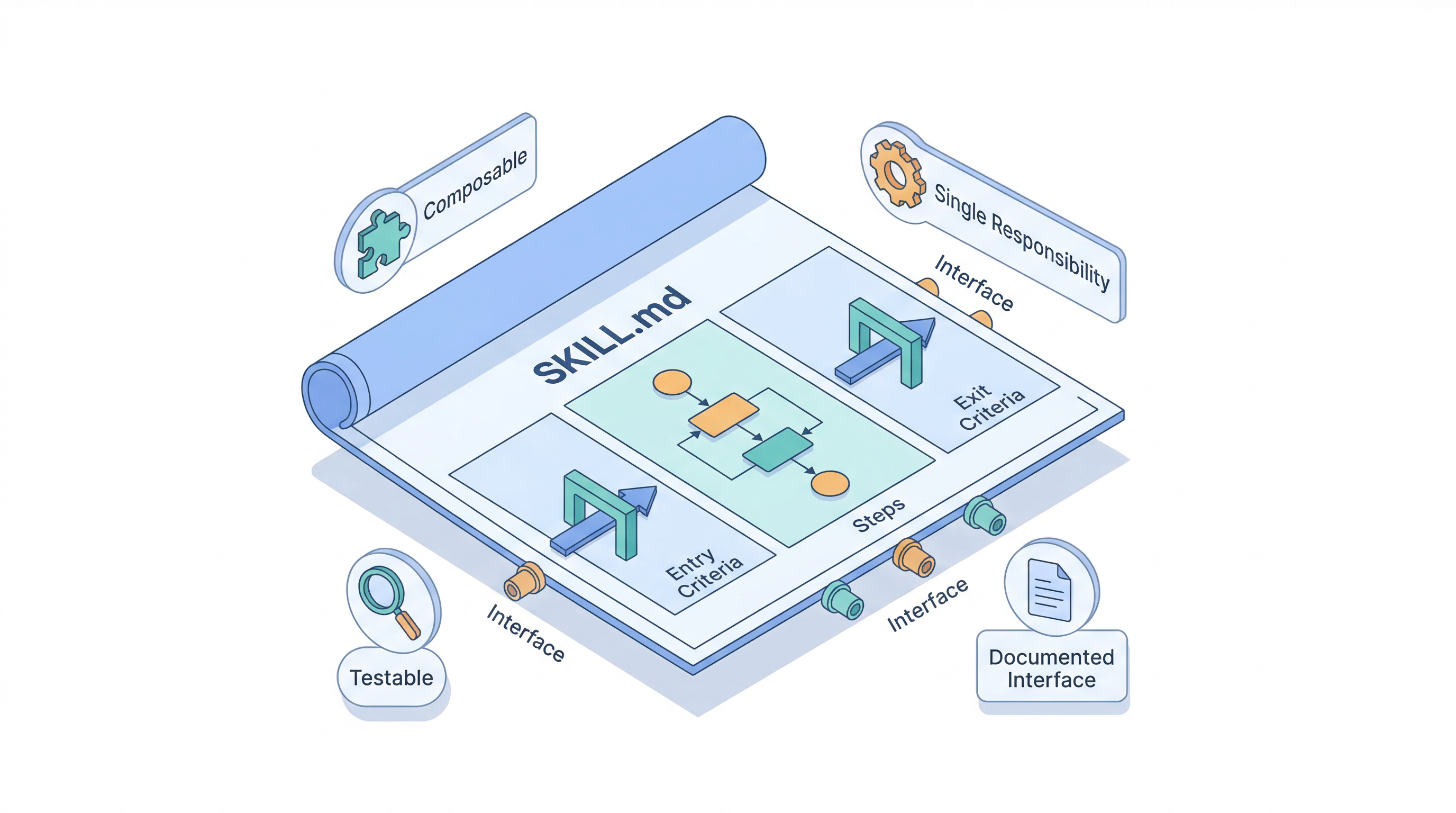
Over the last few posts, I've worked through the five doc types that configure AI agents, why they count as internal documentation, and how to write skills and score them. Each post answered a "what is this file" question. The question I keep getting in response is the next one: what actually goes inside these files, and why?
That's a context-engineering question. Andrej Karpathy coined the term on X in 2025: "Context engineering is the delicate art and science of filling the context window with just the right information for the next step...Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant, and the LLM costs might go up, and performance might come down."
The discipline that makes that balance possible is progressive disclosure: surface only what the agent needs for the current step, and let the rest stay one link or one tool call away. Technical writers already know this move — it's how a good README opens with a summary and pushes the detail out to dedicated pages, or how a tutorial introduces the happy path before the edge cases. Context engineering applies the same idea to the agent's working memory.
This post is the practical version of that idea. Three things every agent needs to be successful, and where each of those three things lives in a repo.