Writing Skills That Agents Can Actually Execute

First, I argued that agent configurations are documentation. Next, I made the case that they're specifically internal documentation and should be managed that way. Both times I covered five doc types: project descriptions, agent definitions, orchestration patterns, skills, and plans/specs.
Of those five, skills are the hardest to write well. Let's walk through how I handled writing and validating skills for Doc Detective's agent tools.
Project descriptions set context. Agent definitions set boundaries. Orchestration patterns describe coordination. But skills tell the agent exactly what to do, step by step—and precision at that level is unforgiving. A vague project description wastes tokens. A vague skill produces wrong output.
Every ambiguous step is a point of failure, a challenge is familiar to anyone who has written a how-to guide or a standard operating procedure. With human readers, ambiguity gets resolved through judgment and context. With agents, ambiguity gets resolved through guessing, except that the agent doesn't know it's guessing.
So how do you write skills that actually work? And once you've written them, how do you know they're any good?
What make a skill
The five agent config doc types exist on a spectrum of prescriptiveness:
| Doc Type | What it specifies | Prescriptiveness |
|---|---|---|
| Project descriptions | Context and conventions | Low — sets the stage |
| Agent definitions | Capabilities and constraints | Medium — defines boundaries |
| Orchestration patterns | Coordination and handoffs | Medium — describes flow |
| Skills | Step-by-step procedures | High — dictates exact actions |
| Plans and specs | Requirements and acceptance criteria | High — defines "done" |
Skills and plans/specs share the high end of that spectrum, but they serve different functions. Plans define what should be produced. Skills define how to produce it. A plan says "write a getting-started guide with these sections." A skill says "here's how to research, draft, edit, and publish a getting-started guide."
That prescriptiveness is what makes skills both powerful and fragile. When they're precise, agents follow them reliably. When they're not, the failure modes are specific to skills:
- Missing entry criteria — The agent starts a task without verifying it has what it needs. Halfway through, it discovers a missing input and either halts or improvises.
- Ambiguous steps — "Review the output" doesn't tell the agent what to check, how to check it, or what constitutes a pass. The agent interprets "review" however its training suggests, which may not be what you intended.
- No exit criteria — Without a definition of "done," the agent may over-deliver, under-deliver, or loop indefinitely.
- Scope creep — A skill that tries to do too many things becomes unpredictable. The agent loses track of where it is in the process or applies the wrong substep to the wrong context.
These failure modes show up regularly. What I've found working with agent skills on documentation projects is that the failure rate correlates directly with how precisely the skill defines its workflow. Vague skills fail in ways that are hard to diagnose because the agent followed its interpretation of the instructions correctly—the instructions just weren't specific enough.
Four design principles
Four principles help keep skills precise and maintainable.
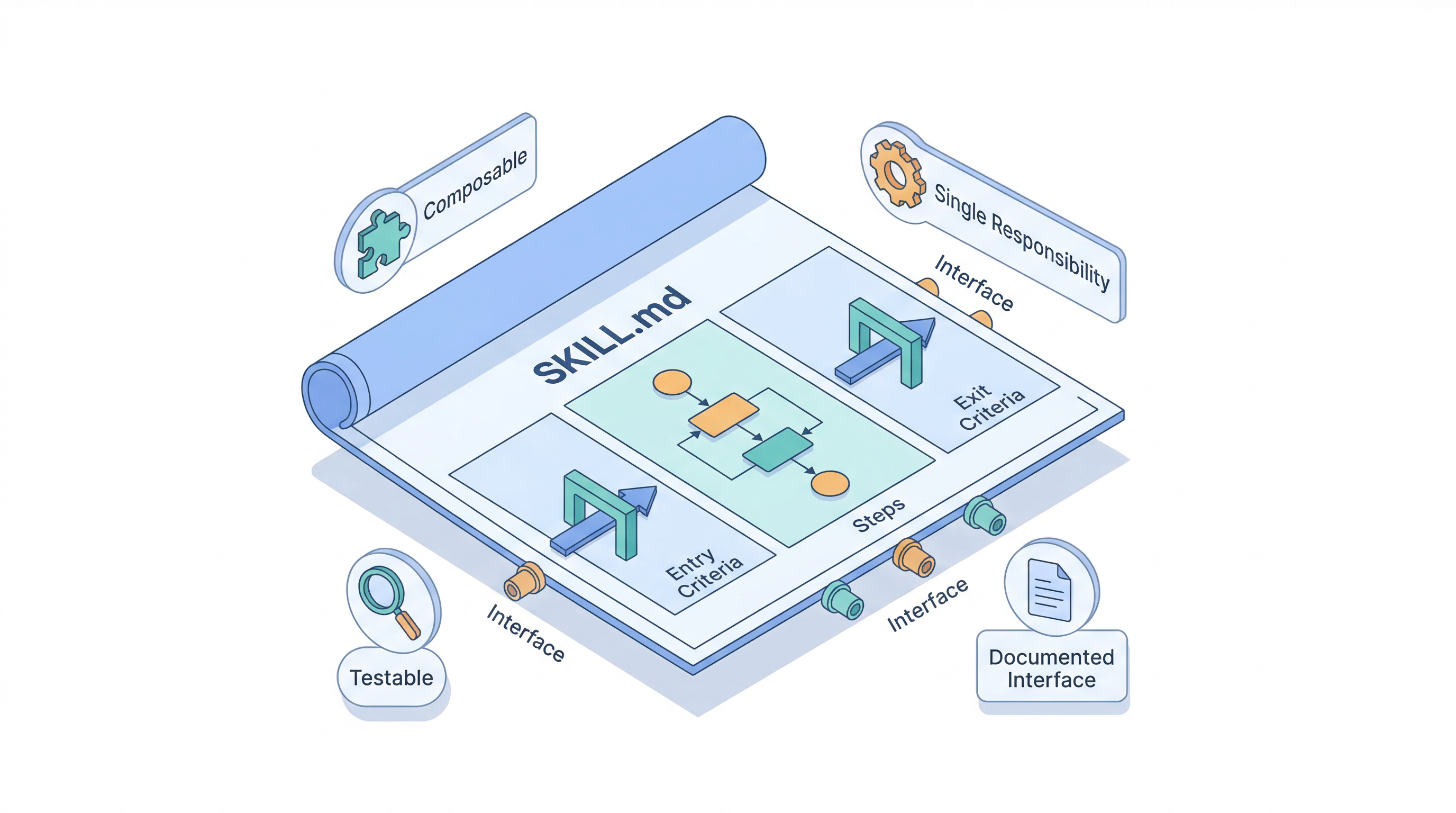
Single responsibility
A skill should do one thing. Doc Detective's agent tools take this approach, with separate skills for each stage of the documentation testing workflow. There isn't one skill to "generate tests and fix failures and inject results." Instead, there are five distinct skills:
doc-detective-generate— Convert documentation procedures into test specificationsdoc-detective-validate— Check that test specs are correctly structureddoc-detective-test— Execute tests and report resultsdoc-detective-inject— Insert test annotations into source documentationdoc-detective-init— Bootstrap the full setup for a new project
Each skill has a defined scope, and the orchestration between them is handled separately. When one skill fails, you know which step failed and why. When you need to improve test generation without touching execution, you update one file.
Testable in isolation
If you can't test a skill on its own, you can't debug it on its own. Each skill should be independently invocable with clear inputs and outputs.
Doc Detective's skills do this by defining explicit entry and exit criteria. For example, the doc-detective-test skill specifies:
**Entry criteria:**
- Documentation input (file path or inline text) is provided
- Input is readable and contains step-by-step procedures
**Exit criteria:**
1. All tests have been executed and results recorded
2. If `--fix`: failing tests have been processed through the fix loop
3. If `--inject`: passing tests have been injected into the source file
4. Final pass/fail counts are accurate and complete
Those criteria are documentation, but they also function as the skill's contract. If the entry criteria aren't met, the skill stops and asks why. If the exit criteria aren't met, the work isn't done, and the agent continues to iterate.
Documented interface
Every skill needs a clear interface that documents what it accepts, what it produces, and what it expects to be true about the environment.
The Agent Skills specification provides an open format for this. A skill is a directory containing a SKILL.md file with YAML frontmatter and a Markdown body:
---
name: doc-detective-test
description: 'Convert documentation procedures into Doc Detective
test specifications, run them, and optionally fix failures'
metadata:
version: '1.1.0'
organization: Doc Detective
references: https://doc-detective.com
---
The body contains the workflow: when to use the skill, entry criteria, exit criteria, execution steps, and examples. Supporting material goes in recognized subdirectories—references/ for background docs, scripts/ for executable helpers, assets/ for templates and data files.
This structure enables progressive disclosure. The SKILL.md file loads into the agent's context when the skill is invoked. Reference files load only when the agent encounters a link to them. That matters because every token in the agent's context window competes with every other token—the same principle that led Vercel to cut their AGENTS.md from 40KB to 8KB.
Composable
Skills should work together without knowing about each other. The doc-detective-test skill invokes doc-detective-generate and doc-detective-validate as part of its workflow, but each of those skills also works independently. You can generate a test spec without executing the spec. You can validate a spec without generating it first.
Composability is what allows orchestration patterns to evolve without rewriting skills. When a team wants to add a review step between generation and execution, they write a new skill and update the orchestration—not the existing skills.
Validating skills with deterministic quality gates
Writing a skill is one challenge. Knowing whether it's good is another.
Until recently, the answer was "try it and see." Run the agent, observe the behavior, tweak the skill, repeat. That feedback loop works, but it's slow, subjective, and doesn't scale.
skill-validator changes this. It's a CLI tool that validates and scores Agent Skill packages, providing deterministic quality checks that catch structural and content issues before an agent ever sees the skill.
What it checks
skill-validator runs five types of analysis:
| Check | What it catches |
|---|---|
| Structure validation | Missing SKILL.md, unrecognized directories, broken internal links, orphan files, token budget overruns, unclosed code fences |
| Content analysis | Word count, code block ratio, imperative sentence ratio, information density, instruction specificity (directive vs. advisory language) |
| Contamination analysis | Cross-language contamination, scope breadth issues |
| Link validation | Dead external HTTP/HTTPS links |
| LLM scoring | Clarity, actionability, token efficiency, scope discipline, directive precision, novelty (requires API key) |
The first four are fully deterministic, meaning no LLM required, no API costs, consistent results every time. They catch structural and content issues like broken references, bloated token counts, vague language, and identifying files an agent will never find (or look for) on its own.
The content analysis is particularly relevant for technical writers because it measures instruction specificity, the ratio of directive language ("must," "always," "never," "required") to advisory language ("may," "consider," "could," "optional"). A high specificity score indicates a skill that tells the agent what to do rather than suggesting possibilities. For skills, directive language generally translates to more predictable agent behavior.
CI integration
skill-validator fits into a CI pipeline the same way a linter or test suite would. Here's a GitHub workflow to validate skills for every PR:
name: Validate Skills
on:
pull_request:
paths:
- "skills/**"
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install skill-validator
run: |
brew install agent-ecosystem/tap/skill-validator
- name: Validate skills
run: |
skill-validator check --strict --emit-annotations skills/
skill-validator check --strict -o markdown skills/ >> "$GITHUB_STEP_SUMMARY"
The --strict flag treats warnings as errors for a binary pass/fail while the --emit-annotations flag surfaces errors inline in the PR diff. The markdown output goes to the GitHub Actions job summary. The same PR review workflow teams already use for code now applies to skills.
Doc Detective uses this pattern with a script that runs skill-validator check --strict against all skills on every change.
Beyond structure: scoring skill quality
skill-validator also supports LLM-as-judge scoring across dimensions like clarity, actionability, token efficiency, and novelty. Scoring opens up questions about what "good" actually means for a skill, how different models perceive the same instructions, and whether novelty—content that goes beyond what an LLM already knows—is a reliable predictor of skill value. That's its own discussion, and one I'll dig into in a future post.
Getting started
Start small:
-
Pick one repeatable task that an agent currently handles without explicit guidance. Document it as a skill with entry criteria, steps, and exit criteria.
-
Validate it. Install skill-validator and run
skill-validator checkagainst your skill. Fix what it finds. -
Test it with the agent. Invoke the skill explicitly and observe whether the agent follows it as written. Where it deviates, the skill is probably ambiguous.
-
Add validation to CI. Once you have a few skills, the CI integration keeps them from degrading as the project evolves.
Perhaps unsurprisingly, this is the same pattern I described for project descriptions: start with one file, observe how agents respond, iterate. The difference is that skills demand more precision because they're more prescriptive. That higher quality bar makes deterministic validation tooling valuable; you get feedback on skill quality before the agent runs, not after.
Docs all the way down
The files that configure AI agents are documentation. They're internal documentation, and they need lifecycle management. Like othe kinds of docs, there are best practices to adhere to, and there are tools (at least in the case of skills) to help us follow those practices.
Documentation skills transfer. Writing clear procedures, defining interfaces, structuring information for the right audience, and knowing what to include and what to leave out are more valuable than ever, especially because our new readers are AI models. The bar for precision goes up, but the underlying discipline stays the same.
Skills are where documentation precision meets automated execution. The design principles and validation tooling described here are still early, but they're converging on a pattern: treat skills like any other professional deliverable, with structure, quality gates, and review.
Oh, and if you're curious about how Doc Detective's skills work to enable AI-assisted test generation for your docs, I'll be writing about that soon on docsastests.com.